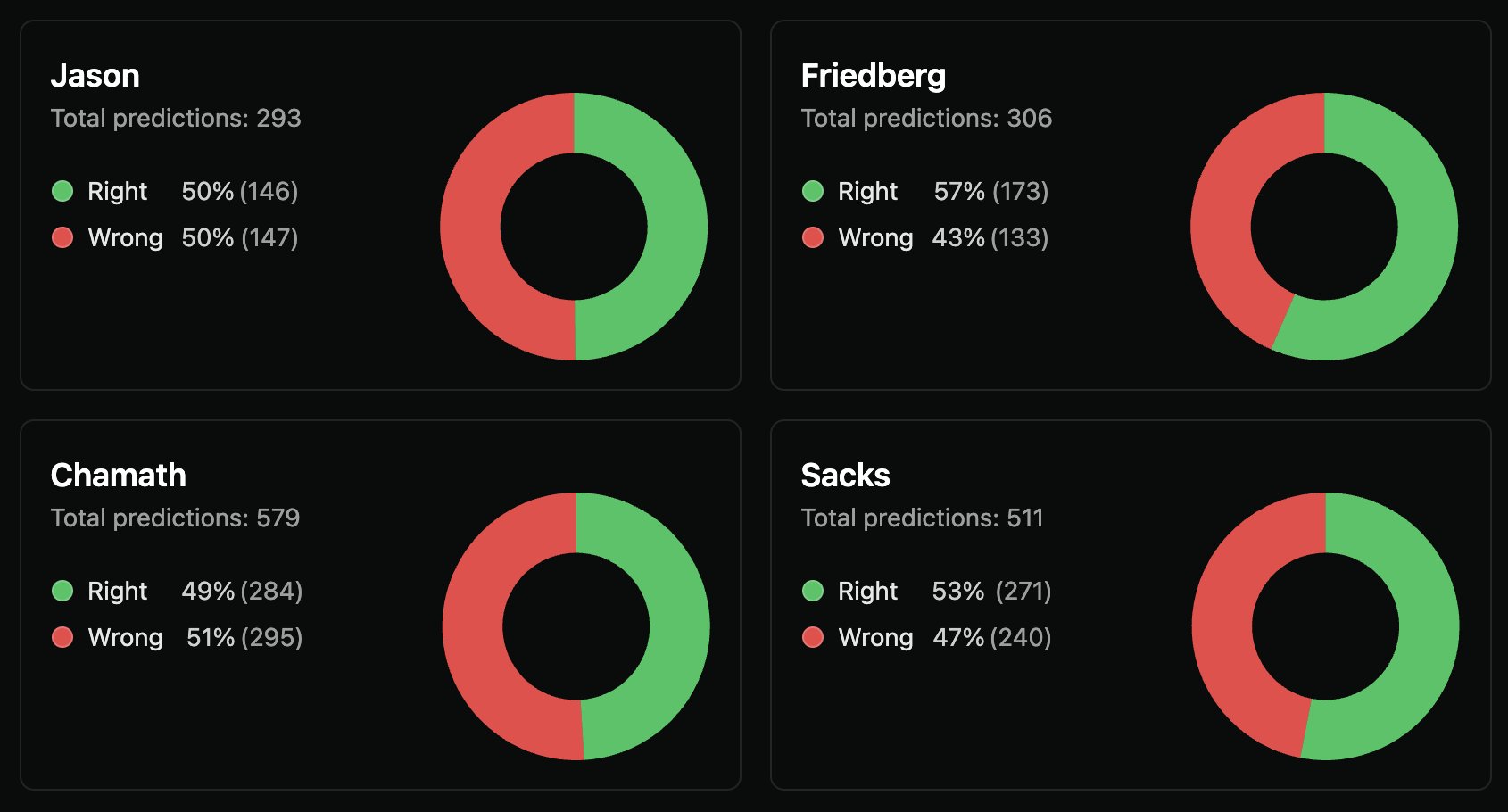
Chamath has the lowest prediction accuracy on the All-In Podcast.
Friedberg has the best overall. Jason was terrible but is improving. Sacks is the best on AI topics.
At least those are the findings of an AI system I built to automatically extract and grade every prediction.
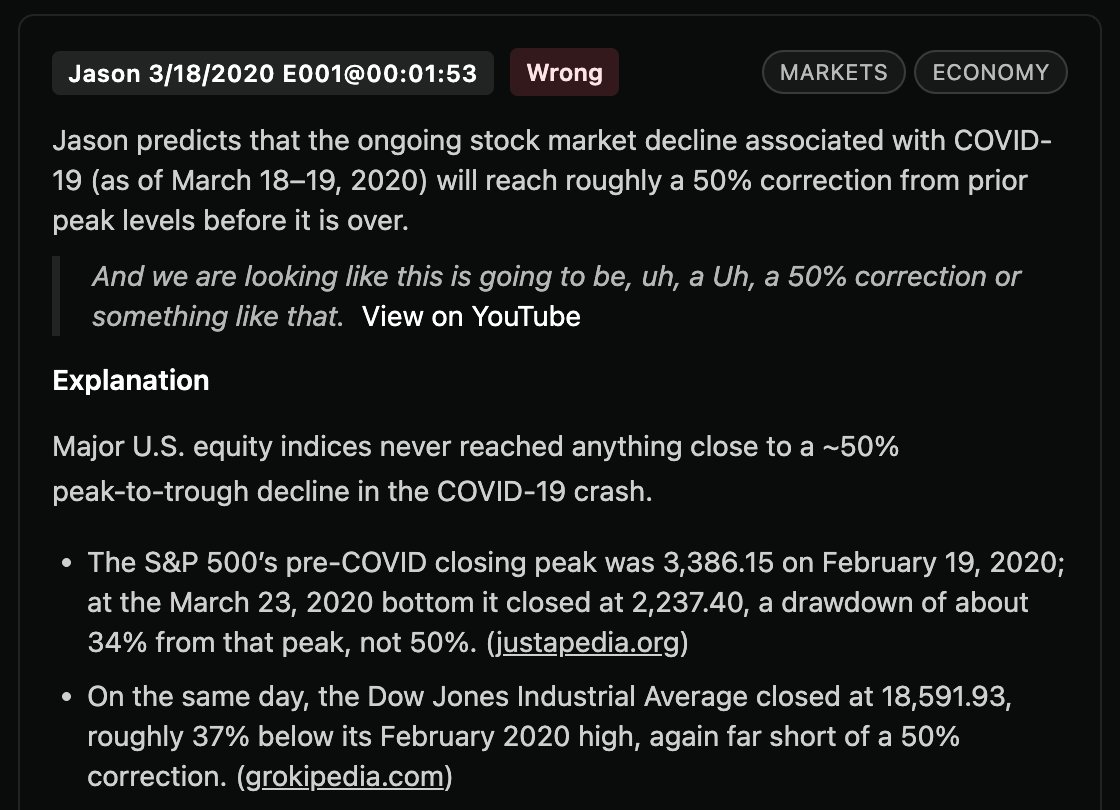
For each prediction, the system captures the exact quote, a cleaned-up summary, topic tags, and then a final verdict with citations generated by an LLM using reasoning + web search.
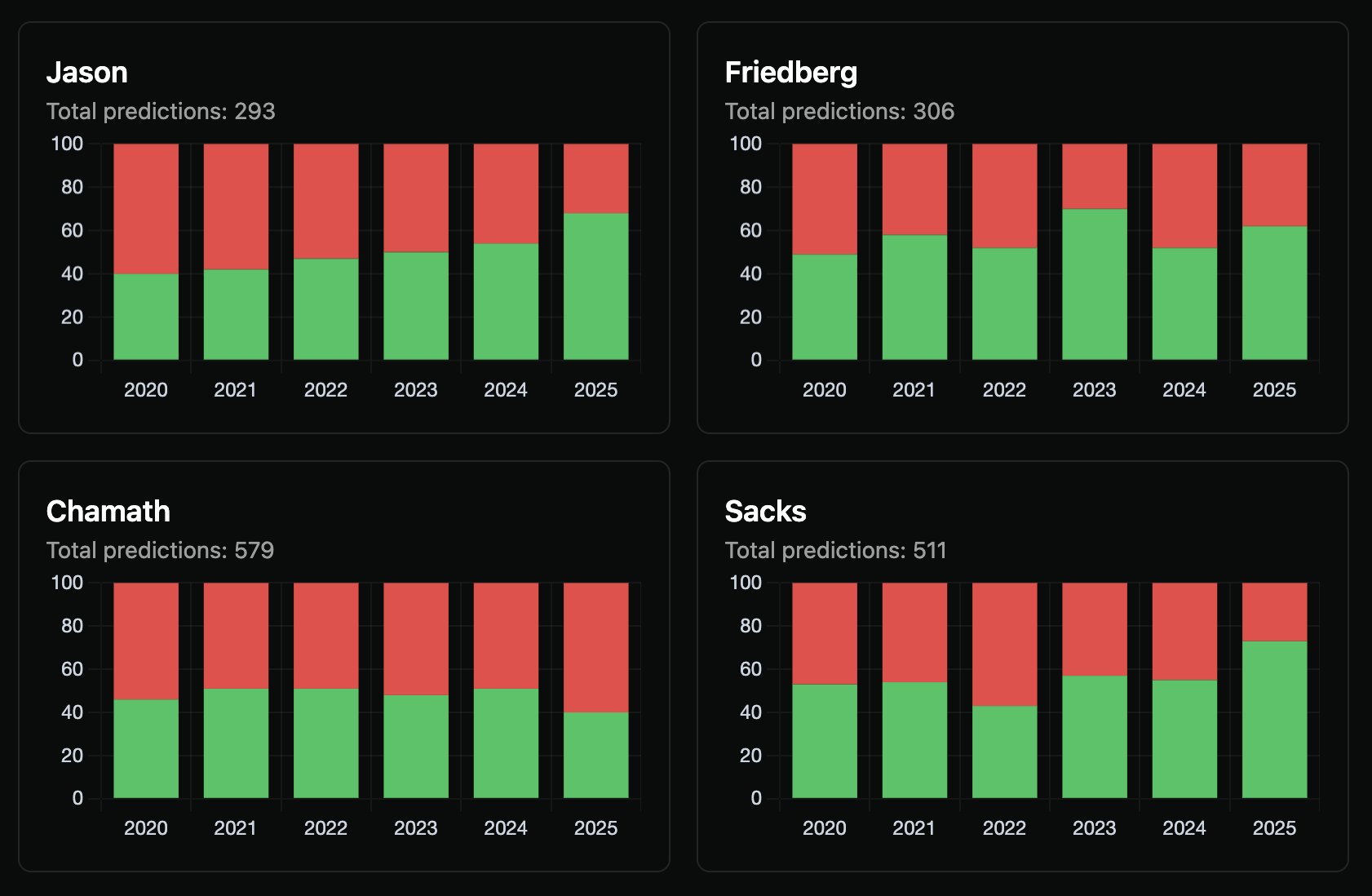
One surprise: most hosts don’t fare much better than a coin flip overall. But segmenting by year starts to reveal interesting trends – like Jason climbing from 40% accuracy in 2020 to 68% so far in 2025.
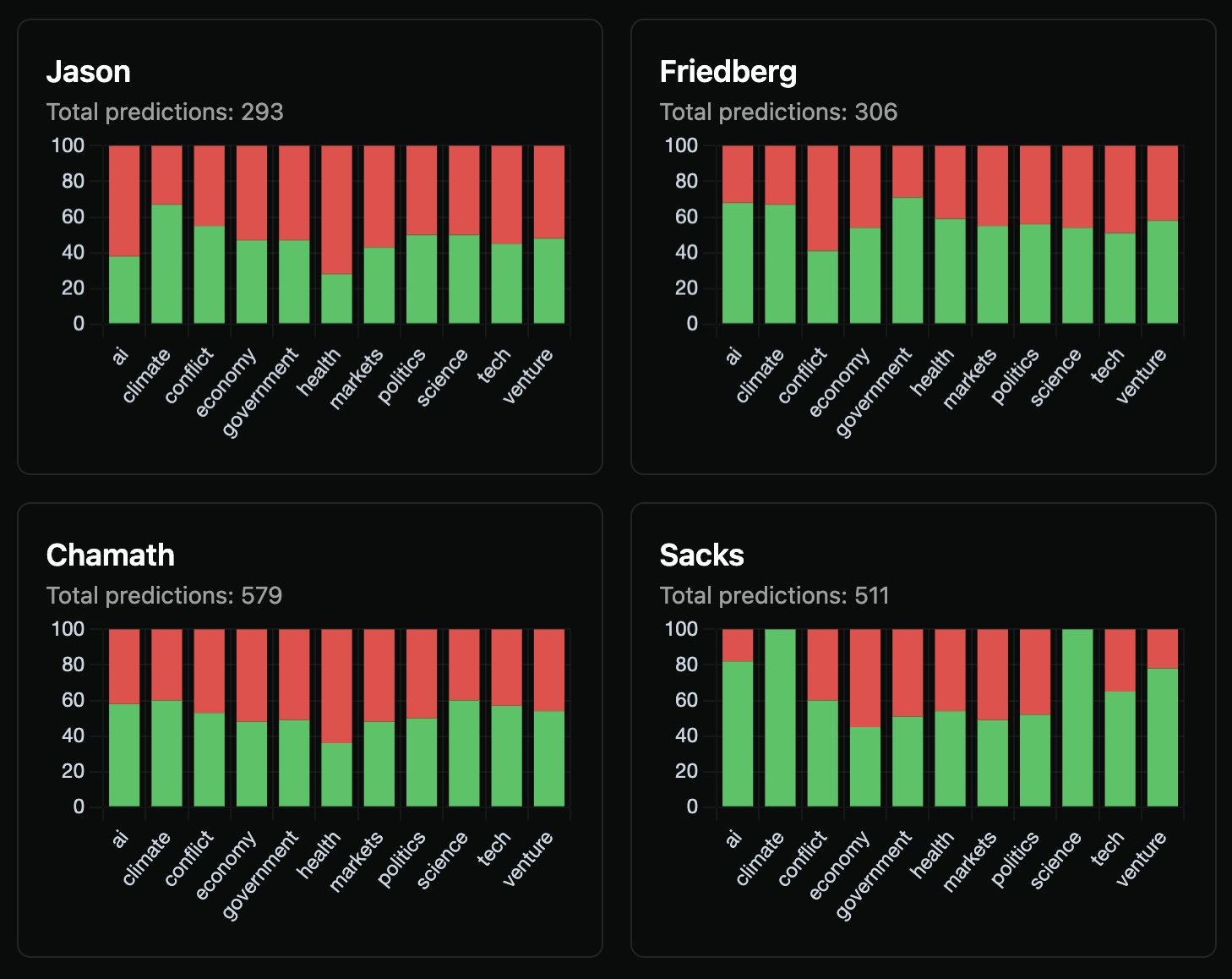
Breaking things out by topic also shows distinct strengths. Friedberg spikes on economy, markets, government, & politics. Sacks spikes on AI, tech, and venture.
To check for potential LLM bias, I ran the evaluations through both GPT-5.1 and Grok-4.1. The models agree on 89% of Right vs Wrong grades. When they disagree, Grok is more likely to grade as Wrong. Even on political predictions, both models assign the same number of Right grades.
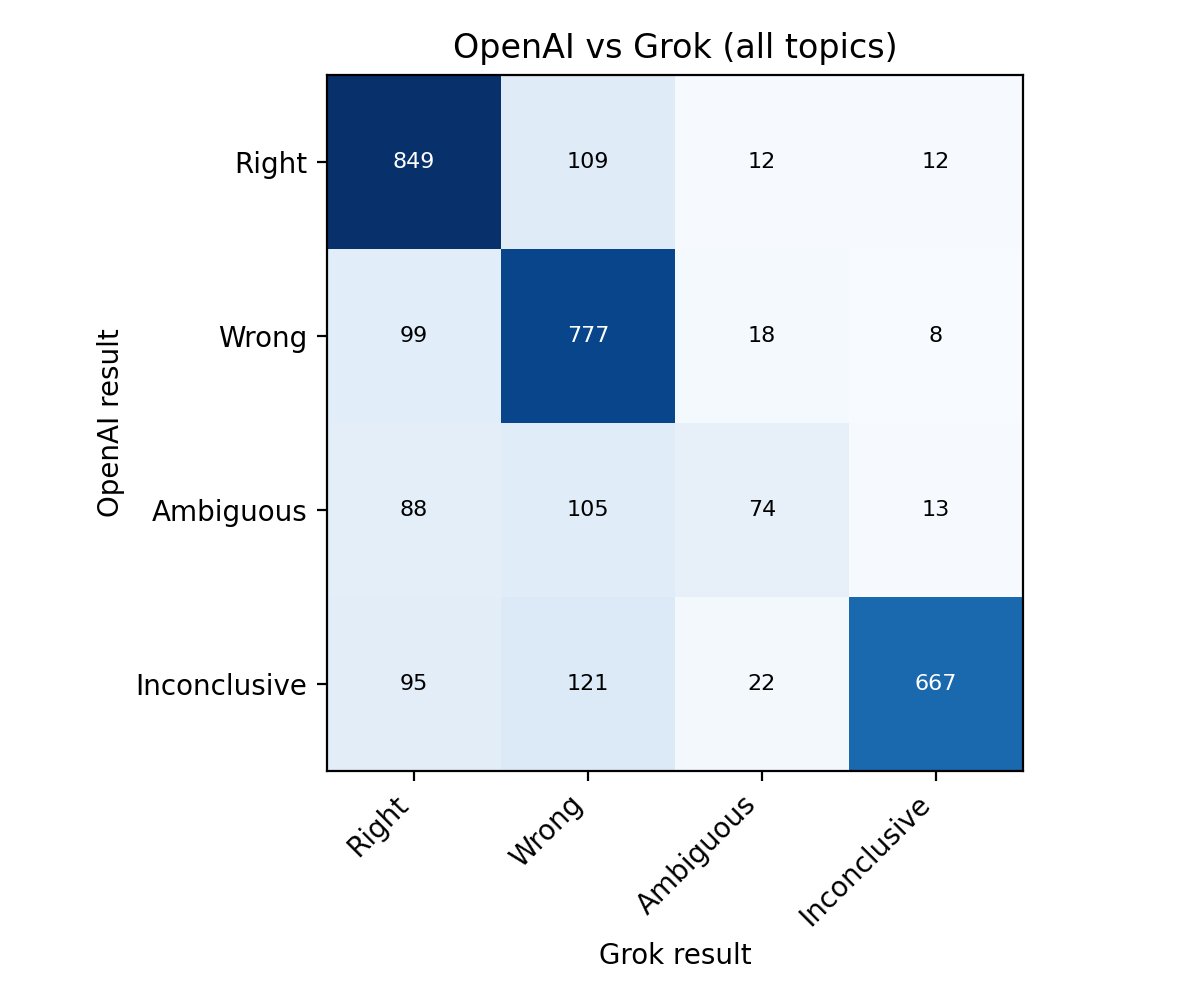
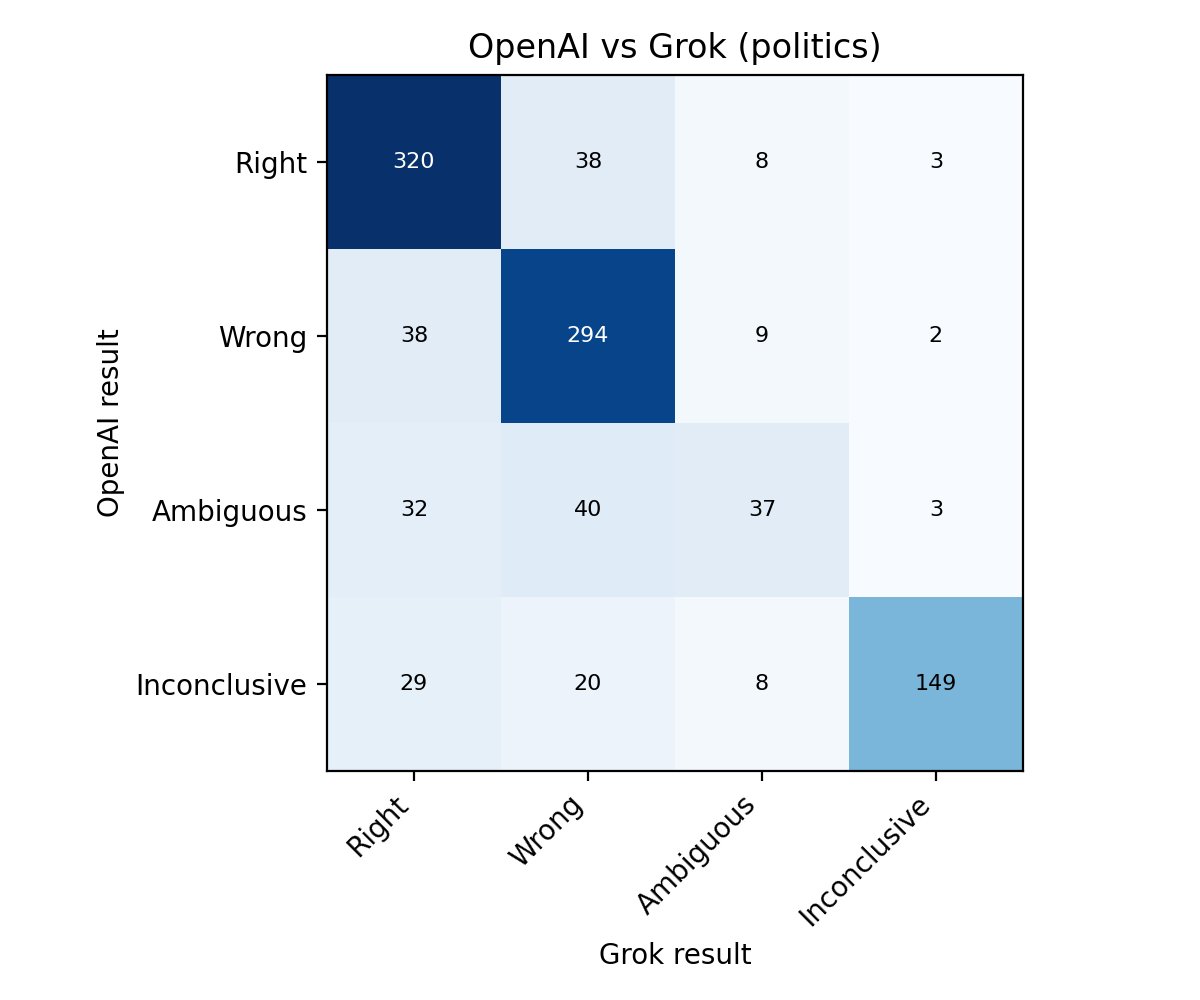
Much has been written about how AI might increase misinformation, but I believe it can also improve the situation and create accountability via automated research and fact-checking. This project was an experiment in that direction.
The open-source code can be found at github.com/schnerd/podcast-predictions…
The system — transcription, embedding-based speaker ID, prediction extraction, validation, and the web app — was built end-to-end in English using Codex CLI.
You can explore the full results at allin-predictions.pages.dev.